MySQL数据库单表千万级别如何优化?
一个公司刚开始的时候业务量不大,一般不会一开始就选择分库分表。当单表数据量达到千万级别的时候,就该考虑了。
这里说一下之前公司遇到过的,单表千万级数据量
数据库是单实例的,这个系统的性能瓶颈主要在数据库,单表的数据量已经达到千万级别,理论上已经是MySQL数据库的极限了。
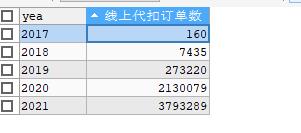
这张图是之前统计各年份线上的订单数,后面其实已经达到3千万了。
订单表是单表,如果遇到复杂业务需要多表联查那就肯定很慢了。单实例MySQL的数据文件都已经达到几十个G。
对于这样的情况,该如何进行优化呢?
主从复制,读写分离,分库分表
这个时候只是单纯的给数据库字段加索引,优化SQL语句等这些已经不能起到显著效果了,需要从架构方面入手。
考虑服务器CPU,内存,网络,磁盘IO等硬件配置
这种方式是最快见效的方式,但是不是长久之计,如果业务量继续增加,单表后面还是会撑不住,只能是临时解决问题。所以还是要解决单表数据量大的问题。
版权声明:本博客所有文章除特殊声明外,转载请注明出处 Mr Xue的博客!